Turborepo로 모노레포에 엔진을 달아보자
최근 개발 업계에서는 모노레포에 대한 관심이 높아지고 있으며, 이는 특히 프론트엔드 분야에서 두드러지게 나타나고 있다. 이는 아마도 폴리레포 방식보다 모노레포 방식이 프로젝트 관리에 있어 여러 가지 이점이 있기 때문일 것이다. 필자 역시 현재 프로젝트에서 모노레포 방식을 채택하고 있다. 그러나 필자의 경험에 따르면, 앞서 언급한 모노레포의 장점은 반정도 만 맞는 말이다. 실제로 모노레포 방식을 기본적으로 채택하면, 프로젝트 관리는 폴리레포보다 더 어려워진다. 그러므로, 모노레포를 통해 프로젝트 관리의 이점을 얻으려면, 모노레포를 효율적으로 사용할 수 있는 도구와의 결합이 필수적이다.
오늘 소개할 Turborepo는 이러한 도구 중 하나로, 모노레포의 이점을 극대화시킬 수 있는 강력한 기술이다. 이번 포스팅에서는 필자의 프로젝트에 Turborepo를 도입하여 프로젝트를 개선한 경험을 공유하고자 한다.
왜 모노레포인가?
프로젝트의 코드베이스를 관리하는 방법은 크게 두 가지이다. 첫 번째인 모노레포는 여러 프로젝트를 단일 코드베이스에서 저장하고 관리하는 방식이다. 반면, 폴리레포는 각 프로젝트마다 별도의 저장소를 가지고 버전을 관리하는 방식이다.
최근에 모노레포에 대한 관심이 높아진 이유는 폴리레포에서 코드 공유와 의존성 관리가 어렵기 때문이다. 예를 들어, 'app', 'docs', 'shared-utils'라는 세 개의 프로젝트가 폴리레포 구조에서 각각 별도의 저장소에 존재한다고 가정해보자. 'app'과 'docs'는 모두 npm을 통해 'shared-utils'에 의존하고 있다.
이 구조에서 'shared-utils'에서 치명적인 버그가 발견되어 수정이 필요한 상황이 발생한다면 아래와 같은 프로세스를 거칠 것이다.
- 'shared-utils'의 오류를 수정 후 커밋
- 'shared-utils'를 npm에 다시 게시
- 'app'에서 'shared-utils'에 대한 업데이트를 수행 후 커밋
- 'docs'에서 'shared-utils'에 대한 업데이트를 수행 후 커밋
현재는 'app'과 'docs'만 존재하지만, 'shared-utils'에 의존하는 프로젝트가 더 많아지면 과정은 더 복잡해질 것이다.
게다가 이런 구조에서는 다소 철학적인 문제도 존재한다. 'app'과 'docs'가 'shared-utils'가 수정되었는지에 대해 정말로 알아야 할까? 'app'과 'docs'는 아마 'shared-utils'보다 고수준의 프로젝트일 것이며, 'shared-utils' 외에도 수많은 의존성을 가질 것이다. 그들 모두에 대한 변경 사항을 관리하게 된다면 매우 어려움이 생길 수 있다. 'app'과 'docs'의 입장에서는 'shared-utils'가 정해진 인터페이스에 맞는 기능을 제공하기만 하면 된다. 'shared-utils'가 변경되었는지는 관심사가 아니다. 하지만 폴리레포 구조에서 npm을 통해 배포하면 버전 관리가 필요해지기 때문에 'app'과 'docs'는 'shared-utils'의 변경 사항을 어쩔 수 없이 알아야만 한다(그래야만 직접 업데이트할 수 있다).
그러나 만일 'app', 'docs', 'shared-utils'의 모노레포 구조라면, 'shared-utils'에서 치명적인 버그가 발생하더라도 "‘shared-utils’의 오류를 수정 후 커밋" 과정만 수행하면 충분하다. 'npm'에 의존하지 않아 버전 관리가 필요 없다. 'shared-utils'는 더 이상 어떤 프로젝트가 자신을 사용하는지를 일일이 알고, 그들에게 변경 요청을 보낼 필요가 없다. 또한 'app', 'docs'는 'shared-utils'의 변경 여부에 대해 더 이상 신경 쓸 필요가 없다. 의존 관계가 프로젝트 수준에 맞게 올바르게 바로 잡혔다.
나는 왜 모노레포를 선택했는가?
보통 모노레포를 구성할 때 프론트엔드와 백엔드를 별도로 분리하여 관리하는 경우가 많지만, 필자는 프론트엔드와 백엔드 둘 다 모노레포, 즉 하나의 저장소에서 관리하였다
이런 결정을 내린 가장 큰 이유는, 프론트엔드와 백엔드가 모두 JS 기반인 NextJS와 NestJS를 사용했기 때문이다. 즉 프론트엔드와 백엔드 모두에서 중복된 코드를 따로 패키지로 분리하여 재사용할 수 있다. 특히, 예전부터 프론트엔드와 백엔드에서 서로 다른 언어가 아닌, JS 코드베이스로 작성하면 '비즈니스 규칙' 같은 비즈니스 로직을 중복해서 관리하지 않고 재사용할 수 있을 것이라는 생각을 가지고 있었는데 이번 기회에 이를 실제로 구현하고 경험해보고 싶었다.
비즈니스 규칙은 대개 서버에 위치하지만, 다양한 이유로 프론트엔드에서도 활용해야 하는 경우가 빈번하다. 비즈니스 규칙은 항상 일정하고 최신 상태를 유지해야 하기 때문에, 중복 코드로 작성하면 관리가 어려워지는 문제가 있다. 이 문제를 해결하고자 모노레포를 도입한 것이다. 물론, JS 코드베이스를 기반으로 하므로, 비즈니스 규칙 외에도 유틸리티 등 재사용 가능한 경우는 얼마든지 많다.
여기서 언급하는 비즈니스 규칙은 "이름은 빈칸이 될 수 없다"나 "지표는 최대 5개까지만 추가할 수 있다"와 같은 우리가 흔히 아는 상태를 변경하는 비즈니스 로직은 아니지만, 비즈니스 용어로 서술될 수 있는 요구사항을 의미한다
두 번째 이유는 팀 구조를 고려했기 때문이다. 우리 팀은 프론트엔드 개발자 2명, 백엔드 개발자 2명으로 구성되어 있지만, 구조적으로 내가 리더 역할을 맡아 팀을 이끌고 있다. 따라서, 백엔드에 대한 리뷰도 내가 진행해야 하므로, 프론트와 백엔드를 분리하기보다는 하나의 저장소에서 관리하는 것이 더 효율적일 것이라고 생각했다. 부수적인 이유로는 전에 프론트와 백엔드가 프로젝트가 길어질수록 서로 점점 단절되는 사일로 현상을 경험한 적이 있는데, 이러한 문제를 해결하는데 모노레포가 조금은 도움이 되지 않을까 생각이 들어서 이다.
왜 Turborepo인가?
그러나 모노레포에도 단점이 없는 것은 아니다. 모노레포 방식을 사용하면 기본적인 코드베이스 관리가 복잡해지며, 구조가 복잡해지고 불필요하고 반복적인 작업이 증가한다. 특히 CI 파이프라인에서 문제가 두드러진다. 모노레포라도 실제로 작업하는 영역은 하나의 프로젝트에 불과하다. 즉, 실제로 변경된 곳은 하나의 프로젝트일 뿐이다. 그러나 모노레포 구조에서는 모든 프로젝트에 대한 CI 파이프라인, 즉 린트, 빌드, 테스트가 실행된다. 변경된 곳이 하나의 프로젝트에 불과하므로 대부분은 불필요한 작업이 될 것이다. 또한 이 모든 작업은 기본적으로 순차적으로 진행된다. 이로 인해 자원과 시간이 낭비되는 문제가 발생한다.
프로그래밍을 통해 이런 문제를 어떻게든 방지할 수 있지만, 이는 추가적인 관리 부담을 야기한다. 모노레포에 프로젝트가 추가될 때마다 동기화를 해줘야 하기 때문이다. 그래서 모노레포의 장점에도 불구하고 과거에는 폴리레포 구조를 많이 사용했다. 이는 모노레포를 관리하는 도구가 부족했기 때문이다. 그러면 만약 모노레포를 효율적으로 관리할 수 있는 도구가 개발된다면 어떨까?
Turborepo
Turborepo는 모노레포 구조의 유지 관리 부담과 오버헤드를 제거하기 위한 기술이다. Turborepo는 다음 네 가지 주요 특징을 통해 모노레포 관리의 어려움을 해결한다.
- 증분 빌드(Incremental builds): 이미 수행한 작업은 캐시하고, 같은 작업이 다시 발생하면 스킵한다.
- 내용 기반 해싱(Content-aware hashing): 작업을 캐시 할 때, 파일의 타임스탬프가 아닌 내용을 기반으로 한다.
- 병렬 실행(Parallel execution): 작업을 순차적으로 수행하는 대신, CPU 낭비 없이 최대한 병렬적으로 수행한다.
- 원격 캐싱(Remote Caching): 동일한 머신뿐만 아니라 원격에서 수행한 작업도 캐시하여, 다른 머신에서 중복 작업을 수행하지 않는다.
증분 빌드, 내용 기반 해싱, 원격 캐싱을 결합하면 모노레포의 CI 파이프라인 문제를 해결할 수 있다. Turborepo를 사용하면 파일 내용이 동일할 때 이미 수행한 작업을 다시 실행하지 않고 스킵한다. 따라서 모노레포에서 하나의 프로젝트가 수정되었을 때, 나머지 프로젝트는 변경사항이 없어 작업을 한 번 이상 다시 수행하지 않는다. 이에 원격 캐싱 기술을 추가하면, 로컬뿐만 아니라 CI 파이프라인에서도 변경된 부분 외에는 중복된 작업을 수행하지 않게 된다.


과거에는 기본적으로 모든 작업이 순차적으로 실행되었다(아마 의존성 그래프에 대한 정보가 없었기 때문이다). 하지만 Turborepo에서는 병렬 실행을 통해 작업을 순차적으로 수행하는 것이 아니라, 작성한 의존성 그래프에 따라 가능한 최대한 많은 작업을 동시에 수행한다.


나는 왜 Turborepo를 선택했는가?
필자가 모노레포를 직접 사용하면서 불편하다고 느낀 점은 크게 두 가지이다. 첫 번째는 dev 모드를 활성화하는 것이다. 내 프로젝트는 프론트엔드와 백엔드 모두가 하나의 레포에 있어 dev 모드를 실행하려면 서버 인프라, API 서버, 웹 서버(Next)를 모두 작동시켜야 한다. 그러므로 각 프로젝트 경로에서 직접 실행해야 한다. 이는 크게 복잡하거나 긴 작업은 아니지만, 반복적인 작업이 필요하여 불편함을 느끼고 있었다. 그래서 루트에서 하나의 스크립트 명령으로 dev 모드를 구동하는 데 필요한 모든 것을 실행할 수 있도록 하는 것이 필요했다. 물론 이 작업은 npm과 같은 패키지 매니저의 workspace로도 수행할 수도 있지만, turborepo를 사용하면 의존성 관계를 쉽게 관리할 수 있어 관리가 더욱 편리해져서 turborepo를 사용했다,
더 중요한 두 번째 문제는 앞서 설명한 모노레포의 CI 파이프라인에서 중복된 작업이 발생하는 것이다. 프로젝트가 초기 단계에는 테스트와 빌드 시간이 짧아 문제가 되지 않았지만, 프로젝트가 커짐에 따라 배포 대기 시간이 점점 길어지는 문제가 생겼다. 프로그래밍을 통해 빌드를 최적화할 수는 있지만, 관리가 점점 어려워질 것이라고 생각했다. turborepo는 복잡한 프로그래밍 없이 중복 작업을 스킵할 수 있어, 파이프라인 시간을 획기적으로 줄일 수 있다고 판단하여 도입을 결정하게 되었다.
Turborepo 도입 결과
작업 그래프(The Task Graph)
turborepo를 사용하여 루트 디렉토리에서 dev 모드를 활성화하는 스크립트를 만들려면, 작업 간의 종속성을 명시하여 turborepo가 Task Graph를 생성할 수 있게 해야 한다. 종속성을 명시하는 방법은 루트 디렉토리에 turbo.json 파일을 생성하고, 그 안에 pipeline 속성을 작성하는 것이다.
{
"$schema": "<https://turbo.build/schema.json>",
"pipeline": {
"start:dev": {
"dependsOn": ["api#infra"],
"cache": false
},
"infra": {
"cache": false
}
}
}
turbo.json에 start:dev 명령을 추가하고, 이 명령이 api 프로젝트의 infra에 의존하도록 설정했다. 즉 turbo run start:dev 명령을 실행하면, api 프로젝트의 infra를 먼저 실행한 다음에 web과 api를 각각 실행하게 된다. dev 모드에서는 캐시가 필요하지 않으므로 캐시는 비활성화하였다.
마지막으로 팀원들이 쉽게 사용할 수 있도록 루트 디렉토리의 package.json에 스크립트를 작성해두면 좋다. 이렇게 되면 turborepo를 모르는 팀원도 루트 디렉토리에서 `npm run start:dev` 명령어를 실행하면 누구나 개발 모드를 시작하고 작업을 바로 시작할 수 있다.
// package.json
{
"scripts": {
"start:dev": "turbo run start:dev"
}
}
이제 루트에서 스크립트 명령어를 입력하면 인프라, API, 웹을 일일이 켤 필요 없이 바로 작업을 시작할 수 있습니다. 또한, 새로운 팀원에게 개발 모드를 실행하는 방법을 일일이 알려줄 필요도 없다(인프라를 켜야 하는지, 어떻게 켜야 하는지 설명할 필요가 없다). 마지막으로 개발 모드 실행을 위해 추가적은 작업이 생겨도 turbo.json에 종속성만 명시하면 되기 때문에 관리가 매우 쉽다.
CI/CD 파이프라인 개선하기
turborepo의 task graph는 매 우 강력한 기술이지만, turborepo의 가장 큰 특징은 remote cache를 통해 여러 머신에서도 증분 빌드가 가능하다는 점이다. 이는 특정 CI 파이프라인의 수행 시간을 크게 단축시키고, 자원을 절약하는 데 도움이 된다. 또한, turborepo의 캐시는 타임스탬프가 아닌 내용(content) 기반으로 캐싱을 하기 때문에, 같은 내용으로 build, test, lint 등의 작업을 한 번이라도 수행했다면, 어떤 머신에서도 동일한 작업을 중복해서 수행하지 않는다.
또 개인적으로 Turborepo를 CI/CD 파이프라인에 적용하면서 느낀 다른 장점 중 하나는 빌드와 같은 작업이 캐시되므로, 다양한 파이프라인을 더 독립적으로 관리하기 용이해졌다는 것이다. 파이프라인 구성 시 종종 빌드에 많은 시간이 소요되어 환경을 독립적으로 구성하기보다는 빌드 작업이 진행되는 환경에 이어서 작업을 설정하는 경우가 있는데, 이로 인해 파이프라인이 점점 길어지곤 합니다. 그러나 Turborepo를 사용하면 환경이 변경되어도 캐시된 빌드를 사용할 수 있으므로, 파이프라인을 더욱 독립적으로 구성할 수 있다는 생각이 들었다. 예를들어 함수 값을 임시 변수화하는 것이 아니라 인라인으로 사용하면 코드를 분리하기 쉬운 원리랑 비슷한 느낌이다.
먼저 개선하기전 파이프라인을 보자.

사실 부끄럽게도 현재 코드는 매우 비효율적으로 작성되어 있다. 일부러 그런건 아니고, 가장 기본적인 기능만을 만족하는 최소한의 상태에서 파이프라인이 점차 확장되면서 자연스럽게 비효율적인 파이프라인이 되었다. 이제 Turborepo로 구조를 개선해 보자. 여기서는 Frontend에만 집중해서 봐보도록 하겠다.
name: CI/CD
on:
push:
branches: ['main']
jobs:
inspection:
name: inspection
timeout-minutes: 15
runs-on: ubuntu-latest
env:
TURBO_TOKEN: ${{ secrets.TURBO_TOKEN }}
TURBO_TEAM: ${{ secrets.TURBO_TEAM }}
TURBO_REMOTE_ONLY: true
steps:
- name: Check out code
uses: actions/checkout@v4
with:
fetch-depth: 2
- name: Setup Node.js environment
uses: actions/setup-node@v4
with:
node-version: 20
cache: npm
- name: Install Dependencies
run: npm ci
- name: Test
run: npm run test
- name: Build
run: npm run build
**
deploy-web:
runs-on: ubuntu-latest
needs: inspection
env:
TURBO_TOKEN: ${{ secrets.TURBO_TOKEN }}
TURBO_TEAM: ${{ secrets.TURBO_TEAM }}
TURBO_REMOTE_ONLY: true
VERCEL_ORG_ID: ${{ secrets.VERCEL_ORG_ID }}
VERCEL_PROJECT_ID: ${{ secrets.VERCEL_PROJECT_ID }}
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup Node.js environment
uses: actions/setup-node@v4
with:
node-version: 20
- name: Install Vercel CLI
run: npm install --global vercel@latest
- name: Install Turborepo CLI
run: npm install --global turbo
- name: Vercel link
run: vercel link --yes --token=${{ secrets.VERCEL_ACCESS_TOKEN }} --project=${{ secrets.FINGOO_PROJECT_NAME }}
- name: Pull Vercel Environment Information
run: vercel pull --yes --environment=production --token=${{ secrets.VERCEL_ACCESS_TOKEN }}
- name: Build Project Artifacts
run: vercel build --prod --token=${{ secrets.VERCEL_ACCESS_TOKEN }}
- name: Deploy Project Artifacts to Vercel
run: vercel deploy --prebuilt --prod --token=${{ secrets.VERCEL_ACCESS_TOKEN }}
`inspection` 단계에서는 테스트와 빌드를 수행하여 제품에 문제가 없는지 검사한다. 이 단계를 무사히 통과하면 `deploy-web` 단계에서 Vercel에 프로젝트를 배포한다. 여기서 주목할 점은 `inspection` 단계와 `deploy-web` 단계 모두 빌드를 진행한다는 것이다. 모노레포를 구성하다 보면 이런 상황이 자주 발생한다. 이는 프레임워크마다 자체적인 빌드 프로세스를 가지는 것이 흔하기 때문이다. 이 때문에 파이프라인 스크립트를 각각 따로 구성하면 모노레포의 관리상 이점이 사실상 없어지게 된다.
그러나 Turborepo를 사용하면 이 문제를 해결할 수 있다. `inspection` 단계에서 모노레포의 모든 패키지에 대한 빌드를 수행한 후, 이를 원격 저장소에 캐시하면, 같은 작업이 이후 파이프라인에 존재하더라도 중복하여 수행하지 않는다. 결과적으로 CI 파이프라인 관리가 쉬워지고, 성능이 크게 향상된다. 아래는 Turborepo를 도입한 후 파이프라인의 소요 시간을 측정한 것이다

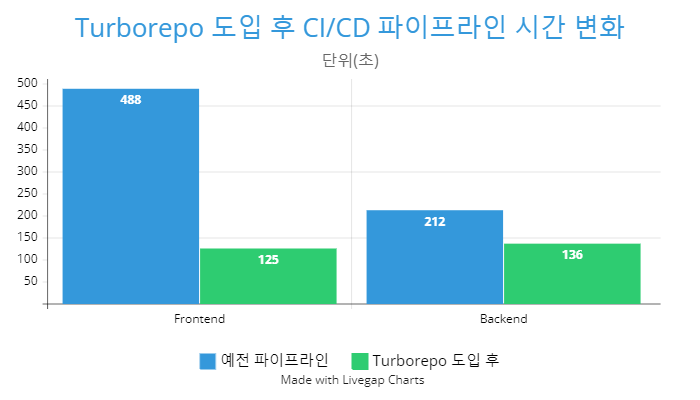
파이프라인의 요소 시간이 Frontend 기준으로 488초에서 125초로 크게 개선되었다. 이는 기존보다 약 3.9배의 시간 절약을 의미합니다. Frontend의 성능이 Backend보다 훨씬 더 상승한 이유는 NextJs의 빌드 시간이 긴 편이므로, 더욱 극적인 효과를 나타난 것으로 보인다.
사실 비밀(?)을 공개하자면, 위의 사진은 최적의 경우(best-case)를 나타낸 것이다. 캐시는 결국 최소 한 번은 실행되어야 하기 때문에, 최악의 경우(worst-case)에서는 기존과 유사한 성능을 보일 것이다(빌드 중복이 없어지므로 기존보다는 물론 더 나은 성능을 보인다). 그러나 Turborepo는 로컬이 아닌 원격 캐시를 지원하기 때문에, 어떤 기계에서든 해당 작업을 한 번만 수행하면 다시 반복하지 않는다. 따라서 최적의 경우가 발생할 확률이 매우 높다.
Turborepo 도입 후기
Turborepo를 도입한 것은 사실 제가 오랜 시간 동안 가지고 있던 야심에서 비롯되었다. 모노레포의 강점인 중복 제거, 코드베이스의 일관성, 종속성, 버전 관리의 편의를 누리면서 동시에 폴리레포처럼 강력한 속도와 성능, 그리고 쾌적한 개발 환경을 누릴 수 있을 것이라 생각했기 때문이다.
사실 프로젝트 초반에 모노레포를 도입했을 때부터 Turborepo 도입을 염두에 두고 있었다. 하지만 모노레포와 Turborepo의 진가는 복잡하고 규모가 있는 프로젝트에서 빛을 발하므로, 프로젝트가 더 성숙해질 때까지 기다릴 필요가 있었다. 마침내 이번에 베타버전 배포를 하면서, 프로젝트가 어느정도 성숙해졌다고 생각해서 Turborepo를 도입하게 되었다(사실 프로젝트 규모로 볼 땐 아직 이른 것 같지만..?).
개인적으로 사용 경험은 아직까지는 아주 만족스럽다. 작업 그래프를 쉽게 관리할 수 있어, 작업에 필요한 것들을 아주 쉽게 스크립트로 만들 수 있었고, 파이프라인 소요시간도 훨씬 단축되었기 때문에 뭔가 눈에 보이지는 않지만 막 방청소를 한 것처럼 개발을 할 때 쾌적한 기분이 든다.
다음으로 개인적으로, Turborepo와 npm이 잘 어울리지 않는다고 생각이 들었다. node_modules의 무자비한 크기도 그렇고, Turborepo와 비슷한 방식인 내용 기반의 content-addressable 방식을 사용하는 pnpm과의 궁합이 더 좋을 것이라는 생각이 들었다(실제로 공식 문서에서는 pnpm을 권장하고 있다). 특히 CI를 구축하면서 아직도 원인을 알 수 없는 문제가 발생했는데, 지금 이 원인이 npm의 유령 의존성(phantom dependency) 때문이 아닐까 생각하고 있다. 그래서 다음에 인프라에 투자할 시간이 있을 때, pnpm으로 마이그레이션을 계획하고 있다.
이번 Turborepo는 관심을 많이 가지고 있었기에 정말 재미있게 작업했던 것 같다. 아직은 Turborepo를 막 도입한 정도의 수준이지만 계속 작업하면서 이해도가 높아지면, 더 많은 것들을 해볼 생각이다. 오늘은 여기서 포스팅을 마치겠다.
'개발 이야기' 카테고리의 다른 글
| 프론트엔드에서 로깅은 왜 필요할까?(ft. 의존성 주입과 선언형 프로그래밍) (32) | 2024.06.04 |
|---|---|
| 프론트엔드는 무엇을 테스트해야 하는가? (39) | 2024.05.28 |
| 실제 사례로 보는 개발자가 좋은 코드를 작성해야 하는 이유 (0) | 2024.05.02 |
| 소프트웨어 개발의 본질에 대하여 (0) | 2023.09.29 |
| [개발 이야기] 다 빈치의 수태고지와 도메인 주도 설계(Domain-Driven Design) (0) | 2023.09.03 |