프론트엔드는 무엇을 테스트해야 하는가?
"프론트엔드에서도 테스트를 해야 하는가?"라는 짧은 질문에 대한 답은 분명하게 "예"이다. 그러나 내 경험에 따르면, 테스트 코드를 작성하는 프론트엔드 개발자는 아직도 소수이다.
내가 진행하는 프로젝트에서는 테스트가 작성되지 않은 코드를 '순살 코드'라고 부른다. 이는 최근 화제가 되었던 철근이 빠진 '순살 아파트'에 비유하여 부르는 말이다. 순살 아파트와 순살 코드의 공통점은 언제 무너져도 이상하지 않다는 것이다. 오직 잘 짜인 테스트 코드 만이 변경으로부터 소프트웨어가 안전하게 원하는 의도대로 동작할 수 있음을 보장할 수 있다.
부끄럽지만 나도 몇 년 전까지는 테스트 코드의 중요성을 잘 알지 못했다. 특히 프론트엔드와는 무관한 이야기라고 생각했다. 하지만 기능이 안전하게 의도대로 작동함을 보장해야 하는 책임은 당연히 프론트엔드 개발자에게도 있다.
프론트엔드에서 테스트가 중요함에도 많은 사람들이 테스트 코드를 짜지 않는 이유로는 아마 프론트엔드에서 테스트 코드를 짜는 게 어렵기 때문일 것이다. 프론트엔드는 다른 외부 요소들에 본질적으로 의존적이며, 동작을 재현하기 어렵기 때문에 테스트를 작성하기 어렵다. 그렇기 때문에 무엇보다 효과적인 테스트 전략이 필요하다.
이 글은 프론트엔드에서 효과적인 테스트를 작성하는 방법에 대해 다룬다. 더욱 구체적으로는, 프론트엔드에서 효과적으로 테스트를 수행하기 위해 필요한 전략, 즉 ‘프론트엔드에서는 무엇을 테스트해야 하는가?’에 대한 나의 생각을 공유하는 글이다. 또한 애플리케이션 코드와 테스트 코드는 서로 영향을 주고받으므로, 테스트에 대해서만 이야기하는 것은 불가능하다. 따라서 이 글에서는 애플리케이션 코드와 테스트 코드에 대해 함께 논의할 것이다.
이 글에는 테스트 코드의 예시가 포함되어 있지만, 테스트 도구의 사용법을 별도로 설명하지는 않는다. 테스트 도구의 사용법이나 유닛 테스트, 통합 테스트 등의 테스트 개념에 대해 알고 싶다면, 다른 자료를 참조하는 것이 좋을 것이다.
마지막으로, 프론트엔드에서 테스트는 필자가 가장 많이 고민하는 주제이다. 프론트엔드 테스트 분야는 최근 계속 발전하고 있으며, 나 또한 더 좋은 방법을 찾고자 노력하고 있다. 이 글을 쓴 이유도 내 생각이 부족할지라도 이를 공유하여 더 훌륭한 사람들로부터 배워 성장하고자 하는 바람이기 때문이다. 따라서 프론트엔드 테스트에 관한 더 좋은 생각이 있다면 꼭 공유해 주시면 정말 감사하겠다.
1. 왜 자동화된 테스트가 중요한가?
내가 진행하는 프로젝트에서는 테스트가 작성되지 않은 코드를 '순살 코드'라고 부른다. 이는 최근 화제가 되었던 철근이 빠진 '순살 아파트'에 비유하여 부르는 말이다. 순살 아파트와 순살 코드의 공통점은 언제 무너져도 이상하지 않다는 것이다. 오직 잘 짜인 테스트 코드 만이 변경으로부터 소프트웨어가 안전하게 원하는 의도대로 동작할 수 있음을 보장할 수 있다.
기능을 개발하는 개발자가 수동으로 기능이 의도대로 동작함을 확인한다면 테스트가 필요 없지 않냐고 반문할 수 있다. 하지만 이는 소프트웨어의 본질적인 속성을 모르고 하는 말이다. 소프트웨어는 변한다. 설령 그 시점에 그 기능이 제대로 동작한다고 할지라도, 앞으로 수많은 변경사항이 발생했을 때도 그 기능이 원래 의도대로 작동함을 보장할 수 있을까? 자동화된 테스트는 이렇듯 회귀 테스트로써의 의미를 가진다. 리팩터링을 하거나 새로운 기능이 추가될 때에도 수동으로 기능이 의도대로 동작함을 확인할 필요 없이 자동화된 테스트 코드를 실행시킴으로써 이를 보장할 수 있다.
또한 테스트는 구현보다 인터페이스에 더 집중하도록 만들어 개발자가 더 좋은 설계를 하도록 도움을 줄 뿐만 아니라, 개발자들이 많은 시간을 쏟는 디버깅 시간을 크게 줄여준다. 더불어, 테스트는 개발자가 개발 완료를 정의하는 기준이 되기도 한다. 즉 테스트는 소프트웨어의 나침반이자 기둥이다.
사실 테스트의 중요성은 필자의 경험 상 백번 듣는 것보다 실제로 경험하는 것이 확실하다. 테스트가 없는 코드는 일정 규모를 넘어서면 기존 코드를 수정하는 것이 거의 불가능해진다. 이는 어떤 버그나 사이드 이펙트가 발생할지 알 수 없기 때문이다. 그러나 자동화된 테스트 코드가 있다면, 기존 코드를 리팩터링 하거나 새로운 기능을 추가하는 일이 더 이상 두려운 일이 아니다. 이런 심리적인 요소가 최종적으로 코드베이스에 매우 큰 차이를 가져온다. 그러니 테스트 코드를 아직 작성해 본 적이 없다면 반드시 작성해 보길 바란다.
프론트엔드도 중요한가요?
테스트의 중요성에도 불구하고, 프론트엔드 분야에서 자동화된 테스트 작성의 필요성에 대한 의문이 여전히 존재한다는 것은 이해하기 어려운 일이다. 아마도 이런 의문은 프론트엔드 테스트가 다른 분야(라이브러리나 백엔드)보다 어렵기 때문에 탄생했을 것이다. 프론트엔드는 본질적으로 애플리케이션의 다른 영역에 의존하고 있어 테스트를 재현하기 어렵다. 하지만 어렵다고 해서 테스트를 하지 않아야 하는 것은 아니다. 비즈니스 로직이 거의 없는 전통적인 웹 사이트의 경우라면 모르겠지만, 프론트엔드 개발자가 존재하는 것 자체가 애플리케이션 프론트에 비즈니스 로직이 있다는 것을 방증한다. 따라서 테스트 코드를 반드시 작성해야 한다.
2. 무엇을 테스트해야 하는가?
테스트를 작성해야 한다는 것은 이견이 없지만, 무엇을 어떻게 테스트할지는 사람마다 의견이 다르다. 프론트엔드는 다른 분야에 비해 테스트하기 더 까다로운 측면이 있기 때문에, 프론트엔드의 특성에 맞는 효과적인 테스트 전략을 구축해야 한다. 여기서 '효과적'이란 가장 적절한 코드의 양으로 "애플리케이션이 의도대로 동작함을 검증"하는 테스트의 목적을 달성하는 것을 의미한다. 어떻게 하면 효과적으로 프론트엔드에서 테스트 코드를 작성할 수 있을까?
테스트 피라미드는 유효한가?
테스트 전략에 대해서 가장 유명한 것은 아마 마틴 파울러의 테스트 피라미드 일 것이다. 테스트 피라미드는 아래에서 위로 단위, 통합, E2E 테스트로 이뤄지며, 위로 올라갈수록 테스트 작성 및 실행 속도가 느려지고 실행 및 유지 관리 비용이 더 높아지기 때문에, 단위 테스트에 더 많이 투자하는 전략이다. 이 전략이 과연 프론트엔드에서도 유효한지, 예시를 통해 확인해 보자
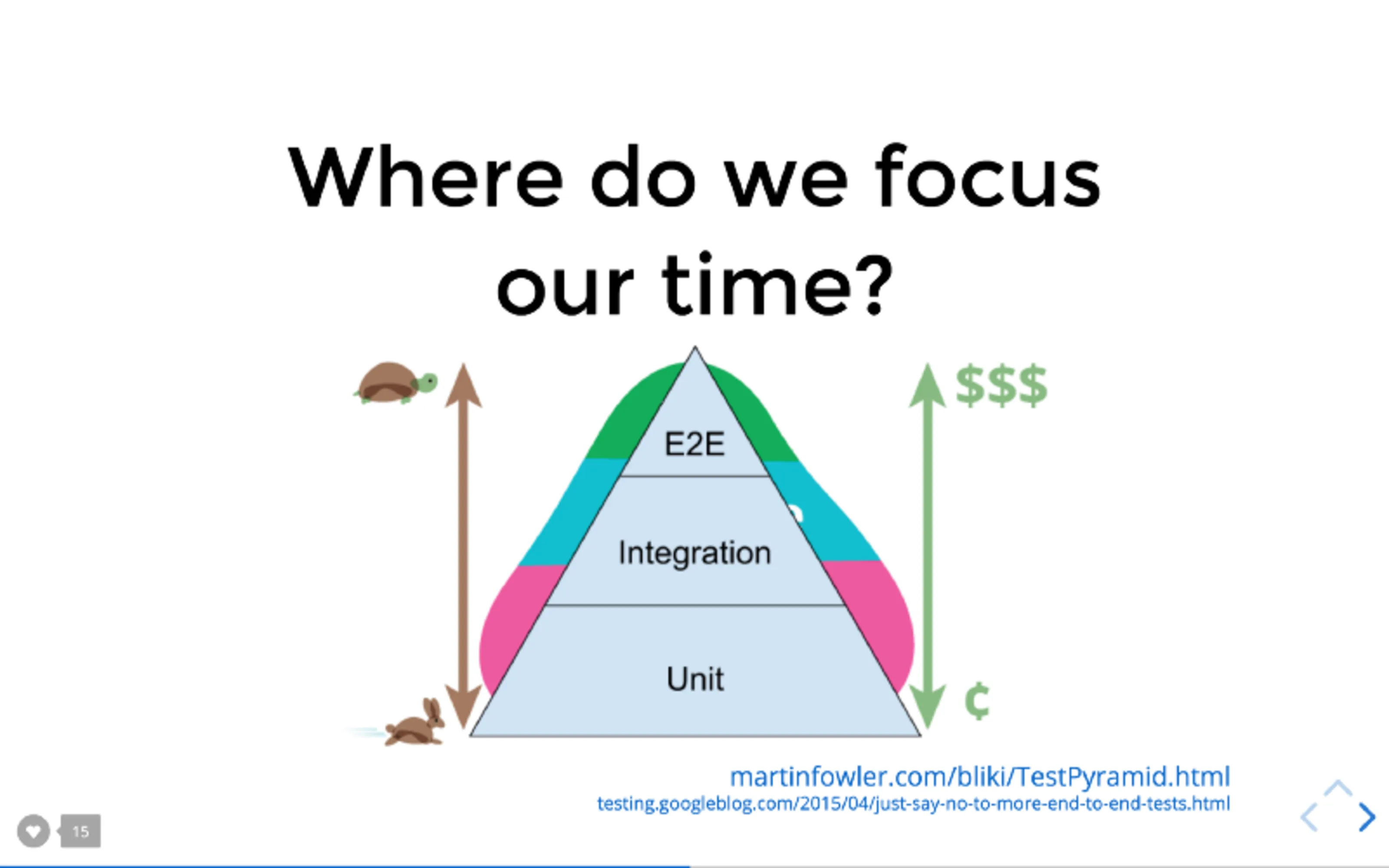
프론트엔드에서 '단위 테스트'라고 하면 무엇이 있을까? 가장 먼저 생각나는 것은 비즈니스 로직이 담긴 커스텀 훅이다. 이를 비즈니스 훅이라고 부르며 아래와 같다.
// 비즈니스 훅 예시, IndicatorBoardMetadata는 도메인 언어이다.
export const useIndicatorBoardMetadataList = () => {
const { data: indicatorBoardMetadataList } = useFetchIndicatorBoardMetadataList();
const { trigger: deleteIndicatorBoardMetadataTrigger } = useDeleteIndicatorBoardMetadata();
const convertedIndicatorBoardMetadataList = useMemo(() => {
if (!indicatorBoardMetadataList) return undefined;
return convertIndcatorBoardMetadataList(indicatorBoardMetadataList);
}, [indicatorBoardMetadataList]);
const deleteIndicatorBoardMetadata = async (metadataId: string) => {
deleteIndicatorBoardMetadataTrigger(metadataId, {
optimisticData: (): IndicatorBoardMetadataResponse[] | undefined => {
const newIndicatorBoardMetadataList =
convertedIndicatorBoardMetadataList?.deleteIndicatorBoardMetadata(metadataId);
return newIndicatorBoardMetadataList?.formattedIndicatorBoardMetadataList;
},
revalidate: false,
});
};
// ...
return {
indicatorBoardMetadataList: convertedIndicatorBoardMetadataList,
// ...
deleteIndicatorBoardMetadata,
};
};비즈니스 훅은 IndicatorBoardMetadata 같은 도메인 용어를 사용하고 이에 대한 자료구조를 가지며 이를 수정하는 로직을 담고 있다. 이때 중요한 것은 뷰 로직을 담은 유틸리티 훅과 비즈니스 훅을 명확하게 구분하는 것이다. 비즈니스 훅은 아래와 같이 테스트할 수 있다.
describe('useIndicatorBoardMetadataList', () => {
beforeEach(() => {
// store와 mock database를 초기화한다.
resetAllStore();
resetMockDB();
});
it('메타데이터 리스트를 가져온다', async () => {
// given
const { result } = renderHook(() => useIndicatorBoardMetadataList(), { wrapper });
await waitFor(() => expect(result.current.indicatorBoardMetadataList).not.toBeUndefined());
// when
// then
expect(result.current.indicatorBoardMetadataList).toHaveLength(3);
expect(result.current.indicatorBoardMetadataList?.[0].id).toBe('1');
});
it('메타데이터를 삭제하면, 삭제한 메타데이터를 제외한 메타데이터 리스트를 가져온다.', async () => {
// given
const { result } = renderHook(() => useIndicatorBoardMetadataList(), { wrapper });
await waitFor(() => expect(result.current.indicatorBoardMetadataList).not.toBeUndefined());
// when
await act(() => {
result.current.deleteIndicatorBoardMetadata('1');
});
// then
expect(result.current.indicatorBoardMetadataList).toHaveLength(2);
expect(result.current.indicatorBoardMetadataList?.[0].id).not.toBe('1');
});
});내 생각에 프론트엔드에서는 테스트 피라미드 전략이 그다지 효과적인 전략은 아니라고 생각한다. 이에 대한 이유는 크게 두 가지이다. 먼저, 위의 예시처럼 프론트엔드에서 비즈니스 로직이 얇은 경우가 많다. 대부분의 비즈니스 로직이 서버에 위치하고, 클라이언트에서는 그 상태를 캐시하고 있는 형태이기 때문이다.
두 번째로, 더 중요한 이유는 프론트엔드에서는 비즈니스 로직이 정상적으로 작동하더라도, 소프트웨어가 의도대로 동작한다는 것을 보장하지 않기 때문이다. 이는 비즈니스 로직이 독립적으로 동작하지 않고, 컴포넌트와 같은 UI 요소와 반드시 결합하여 동작하기 때문이다. 즉, 로직과 컴포넌트가 결합되어 제대로 작동하는지 확인해야만 "애플리케이션이 의도한 대로 작동하는지 검증"하는 목표를 달성할 수 있다. 각각의 비즈니스 로직과 UI가 제대로 작동하는지 테스트하는 것은 나쁘지 않지만, 두 요소가 서로 제대로 작동하는지 확인하지 않으면 아무런 효과가 없다.
역 피라미드: 페이지 수준의 E2E 테스트
따라서, 프론트엔드에서는 UI와 비즈니스 로직이 결합된 상태에서 정상 작동하는지를 확인하기 위해 페이지 수준에서 수행하는 E2E 테스트를 주로 작성했다. 즉, 테스트 피라미드가 반대로 뒤집어진 역피라미드 형태로 테스트가 이뤄졌던 것이다. 하지만 마틴 파울러가 지적했듯이, 테스트 피라미드를 올라갈수록 테스트 작성 및 실행 속도가 느려지며, 실행 및 유지 관리 비용도 증가한다. E2E 테스트는 브라우저에 올려 실행되므로 무겁고, 페이지는 자주 변경되기 때문에 테스트 관리가 어렵다. 따라서 독립적이면서 하나의 책임으로 응집된 컴포넌트 수준의 테스트가 필요하다.
적합한 테스트 대상: 도메인 컴포넌트
현재 프론트엔드 개발은 페이지 단위가 아닌 컴포넌트 단위로 이뤄진다. 그렇다면 테스트도 컴포넌트 단위로 이뤄져야 하지 않을까? 그러기 위해서는 독립적이며 응집된 컴포넌트가 필요하다. 내가 도메인 컴포넌트라 불리는 컴포넌트는 독립적이면서 하나의 책임을 수행하기에 프론트엔드에서 테스트 단위로 적절하다. 먼저 도메인 컴포넌트가 무엇인지 살펴보자.
정확한 용어를 찾을 수 없어, 내가 속한 팀에서는 도메인 컴포넌트 혹은 도메인 종속 컴포넌트로 명명하여 부르고 있다
도메인 컴포넌트란
프론트엔드는 크게 비즈니스 로직과 사용자 인터랙션을 위한 UI를 그리는 두 가지 관심사를 가진다. 이 두 부분은 서로 다른 관심사이므로 엄격하게 분리되어야 하며, 이렇게 함으로써 독립성을 유지하고 재사용성을 확보할 수 있다. 하지만 애플리케이션을 제대로 동작시키기 위해서는 어느 지점에서는 이 두 관심사가 결합되어야 한다.
도메인 컴포넌트는 비즈니스 로직과 UI 이 서로 다른 관심사를 연결하는 역할을 담당하는 컴포넌트이다. 도메인 컴포넌트는 비즈니스 hook에서 비즈니스 로직을 가져와 UI를 담당하는 뷰 컴포넌트에 주입한다. 예를 들어 보자
// 도메인 컴포넌트 예시
export default function MetadataDeleteDialog() {
const { deleteIndicatorBoardMetadata } = useIndicatorBoardMetadataList();
const handleClick = (payload) => {
deleteIndicatorBoardMetadata(payload);
};
return (
<AlertDialog dialogKey={DIALOG_KEY.METADATA_DELETE}>
<AlertDialog.Title>Delete Metadata</AlertDialog.Title>
<AlertDialog.Body>Are you sure you want to delete this metadata?</AlertDialog.Body>
<AlertDialog.NegativeButton>Cancel</AlertDialog.NegativeButton>
<AlertDialog.PositiveButton onClick={handleClick}>
Delete
</AlertDialog.PositiveButton>
</AlertDialog>
);
}MetadataDeleteDialog 컴포넌트는 useIndicatorBoardMetadataList 비즈니스 훅에서 메타데이터를 삭제하는 비즈니스 로직을 가져와 AlertDialog라는 뷰 컴포넌트에 주입한다. 이를 통해 사용자는 AlertDialog를 사용하여 메타데이터를 삭제하는 의도를 달성할 수 있다. 이렇듯 도메인 컴포넌트는 도메인에 종속된 이름을 가지고 애플리케이션의 특정한 목적을 수행하는 책임을 가진다. 즉, 도메인 컴포넌트는 같은 컴포넌트이지만 UI를 그리는 뷰 컴포넌트와는 다른 책임을 수행하며, 이 둘은 엄격하게 구분된다
Container/Presentational 패턴과 다른 점
언뜻 보면 전통적인 Container/Presentational 패턴과 크게 다르지 않아 보인다. Container/Presentational 패턴 역시 비즈니스 로직과 뷰를 분리하는 패턴이기 때문이다. 그러나 도메인 컴포넌트는 전통적인 Container와는 다른 역할을 수행한다. 좀 더 정확히 말하면, 도메인 컴포넌트를 통해 Container에 집중된 복잡한 관심사를 한 단계 더 분리한다. 예를 들어, 강의 리스트를 조회하고 추가하고 삭제할 수 있는 간단한 애플리케이션을 만드는 것을 생각해 보자. Container/Presentational 패턴을 사용하여 이를 구현하면, 아래와 같을 것이다.
import { useState } from 'react';
import List from '../view/molecule/list';
import Button from '../view/atom/button/button';
type Lecture = {
id: number;
title: string;
description: string;
};
export default function LectureContainer() {
const [lectures, setLectures] = useState<Lecture[]>([]);
const addLecture = (lecture: Lecture) => {
setLectures([...lectures, lecture]);
};
const handleLectureAdd = () => {
addLecture({
id: lectures.length + 1,
title: 'Lecture Title',
description: 'Lecture Description',
});
};
const hanldeLectureDelete = () => {
setLectures(lectures.slice(0, -1));
};
const render = (lecture: Lecture) => {
return (
<div key={lecture.id}>
<h3>{lecture.title}</h3>
<p>{lecture.description}</p>
</div>
);
};
return (
<div>
<Button onClick={handleLectureAdd}>Add Lecture</Button>
<Button onClick={hanldeLectureDelete}>Delete Lecture</Button>
<List list={lectures} render={render} />
</div>
);
}
LectureContainer 컴포넌트에서는 강의에 관한 상태, 추가 및 삭제 가능한 비즈니스 로직을 정의하고 이를 UI를 담당하는 Presentational 컴포넌트에 주입한다. 이를 컴포넌트 구조로 표현하면 다음과 같다.

Container/Presentational 컴포넌트의 문제는 Container 컴포넌트가 과도하게 많은 관심사를 처리한다는 것이다. Container 컴포넌트에서 상태와 삭제 추가와 같은 비즈니스 로직이 정의되므로, 코드가 많아질 수밖에 없다. 위 예시는 간단한 수준이지만, 예를 들어 강의 수정 기능 추가가 필요하다면 Container 컴포넌트에 로직이 더 추가되어 점차 무거워질 것이다. 또한, Container는 화면에 무엇을 표시할지에 대한 처리도 담당한다. 다른 형태의 뷰를 추가하거나, 수정 버튼을 추가할 때도 Container 컴포넌트에서 작업해야 한다.
이로 인해, Container컴포넌트는 점차 커지고, 비즈니스 로직은 컨테이너에 강하게 결합되어, 독립적으로 테스트할 수 없게 된다. 즉, Container 컴포넌트 전체를 통째로 테스트해야 하며, 이는 테스트를 작성하고 유지보수 하는 것을 어렵게 만든다.
도메인 컴포넌트는 Container와 Presentational 사이에 또 하나의 컴포넌트 계층을 두어 Container에 몰려 있는 관심사를 적절하게 분리함으로써 단일 책임 원칙 즉 컴포넌트가 하나의 책임만 준수하도록 만든다. 도메인 컴포넌트를 작성하여 위 코드를 리팩터링 한다면 아래와 같은 구조가 된다.

Container에 몰려있던 비즈니스 로직을 AddLectureButton과 DeleteLectureButton 같은 도메인 컴포넌트로 분리했다. 즉 Container는 더 이상 비즈니스 로직에 대한 관심사를 처리하지 않으며 정말 단순히 화면에 무엇을 그려줄지에 대한 관심사만 처리하게 된다.
도메인 컴포넌트 관점으로 보면, 더 이상 어느 페이지나 화면에 그려질지에 대해서는 도메인 컴포넌트의 관심사가 아니다. 또한 AddLectureButton 컴포넌트는 강의를 추가하는 책임에만 집중하고, 강의를 삭제할 수 있는지나 강의가 어디에서 보이는지 등은 더 이상 관심사가 아니므로 몰라도 된다. 도메인 컴포넌트는 다른 컴포넌트와 연계되지 않고도 독립적으로 자신의 책임을 수행할 수 있다. 즉 이런 방식으로 도메인 컴포넌트를 계층화하면, 코드를 더 선언적이고 독립적으로 관리할 수 있다.
// 도메인 컴포넌트: 자신의 책임(강의를 추가하는 것)만 집중하여 수행한다.
export default function AddLectureButton() {
const { addLecture } = useLectures();
const handleLectureAdd = () => {
addLecture({
title: 'Lecture Title',
description: 'Lecture Description',
});
};
return <Button onClick={handleLectureAdd}>Add Lecture</Button>;
}
// 컨테이너 컴포넌트: 화면에 어떤 컴포넌트를 그리고, 레이아웃을 만들지에 대한 관심사만 가진다.
export default function LectureContainer() {
return (
<div>
<AddLectureButton />
<DeleteLectureButton />
<LectureList />
</div>
);
}
이렇게 도메인 컴포넌트를 이용해 코드를 분리하면 테스트를 독립적으로 수행할 수 있다. 예를 들어, 강의 추가에 대한 로직을 테스트할 때, 원칙적으로는 AddLectureButton 컴포넌트 외에 다른 컴포넌트는 필요하지 않는다.
테스트뿐만 아니라, 도메인 컴포넌트를 계층화하고 관리하는 것은 코드베이스의 유지보수에도 좋다. 강의 추가 기능에 대한 변경사항이나 새로운 요구사항, 예를 들면 로깅 기능이 추가되어야 한다면, Container/Presentational 구조에서는 상관없는 Container 컴포넌트 코드를 모두 검토해야 한다. 그러나 도메인 컴포넌트가 있다면, AddLectureButton 컴포넌트로 바로 이동하여 변경사항을 처리하면 된다
위의 예시는 간단한 애플리케이션으로, 그 효용성이 크게 드러나지 않을 수 있다. 하지만, 나의 경험 상 복잡한 애플리케이션 개발 시, 도메인 컴포넌트를 별도로 분리하여 관리하면 복잡성을 관리하는 데 큰 도움이 된다는 것을 경험했다. 이후로 이 개념을 프로젝트에 적용하여 컴포넌트를 수직-수평 분할하여 구조적으로 관리하고 있다.
도메인 컴포넌트 테스트
도메인 컴포넌트의 주요 이점 중 하나는 독립적인 테스트를 진행할 수 있다는 점이다. 덕분에 테스트 코드 작성과 유지 보수가 간편하며, 실행 시간도 짧다. 앞서 언급한 MetadataDeleteDialog 컴포넌트에 대한 테스트를 작성해 보자.
describe('MetadataDeleteDialog', () => {
beforeEach(() => {
resetMockDB();
resetAllStore();
// dialog를 화면에 표시하기 위한 뷰 로직을 동작시킨다.
const { result } = renderHook(() => useDialog(DIALOG_KEY.METADATA_DELETE));
act(() => {
result.current.openDialogWithPayload({
id: '1',
});
});
});
it('사용자가 확인 버튼을 클릭하면, 메타데이터 리스트에서 해당 메타데이터가 삭제된다.', async () => {
// given
const user = userEvent.setup();
render(
<>
<MetadataList />
<MetadataDeleteDialog />
</>
);
// when
await user.click(await screen.findByRole('button', { name: 'Confirm' }));
// then
expect(screen.queryByText(/metadata1/i)).toBeNull();
});
});
컴포넌트와 테스트가 독립적이므로, 테스트 코드 작성이 매우 쉽다. 또한, MetadataDeleteDialog 외부의 코드 변경으로 인해 테스트 코드가 깨지지 않는다. 위의 테스트는 정상 동작을 검증하기 위해 MetadataList 컴포넌트에 추가로 의존했지만, 이를 원치 않다면 mock을 관리하고 있다면 mock data를 사용하거나, hook의 state를 확인함으로써 의존성을 제거할 수도 있다.
필자는 현재 프론트엔드에서 도메인 컴포넌트가 테스트 대상으로 가장 적절하다고 생각하며, 이에 중점을 두고 테스트 코드를 작성하고 있다. 그 이유는 경험상 도메인 컴포넌트의 테스트 코드가 가장 효과적으로 "애플리케이션의 의도대로 동작하는지 검증"하는 테스트 목적을 달성할 수 있었기 때문이다.
물론, 저도 아직은 부족한 개발자이기에 당연히 더 나은 방법이 있을 수 있다고 생각한다. 프론트엔드 테스트는 필자가 가장 고민하고 있는 분야 중 하나로, 항상 더 나은 방안이 무엇인지 고민하고 있다. 그러므로 더 좋은 방법이 있다면 꼭 공유해주시면 감사하겠다!
3. 그 외 프론트엔드에서의 여러 테스트
프론트엔드는 사용자와의 상호작용 시 애플리케이션이 의도대로 동작하는지 검증하는 테스트 외에도 여러 테스트가 존재한다. 이들은 비즈니스 로직을 직접적으로 테스트하는 것은 아니지만, 프론트엔드 제품 자체의 품질을 원하는 수준으로 유지하는데 큰 도움이 된다.
UI 테스트(시각적 요소 테스트)
시각적 요소 테스트는 도메인 컴포넌트가 아닌 뷰 컴포넌트에 대해 실행하는 테스트이다. 뷰 컴포넌트 테스트는 크게 2가지로 뷰 로직이 올바르게 수행되는지, 그리고 화면에 정해진 스타일로 올바르게 렌더링 되는지를 확인한다.
시각적 요소 테스트 도구로는 스토리북이라는 훌륭한 도구가 있다. 스토리북을 사용하면 뷰 컴포넌트를 독립적으로 렌더링 할 수 있어, 순수한 뷰 컴포넌트 개발에 큰 도움이 된다. 또한, 스토리북과 크로마틱을 같이 사용하면 시각적 요소 회귀 테스트를 수행할 수 있다. 이는 컴포넌트의 렌더링 된 이미지 스냅샷을 캡처하고, 변경 사항이 발생하면 이를 비교함으로써 시각적 요소가 예상치 못하게 변경되는 문제를 방지해 제품 품질 관리에 도움을 준다.
시각적 요소 회귀 테스트의 또 다른 흥미로운 점은 컴포넌트 개발에 TDD 개발 방법론을 적용할 수 있는 방법을 제공한다는 것이다. 개인적으로 개발에 적용해 보니 경험이 꽤 좋아 뷰 컴포넌트 개발 시 이와 같은 방식을 취하고 있다. 관심이 있다면 아래 링크를 참고해 보자.
https://storybook.js.org/tutorials/visual-testing-handbook/react/ko/vtdd/
(+ Next.js 14 버전에서 RSC에 대한 테스트를 작성할 때, 기존 테스팅 프레임워크와의 호환성 문제가 있다. 그러나 스토리북은 playwright 방식을 사용하기 때문에, 스토리북을 통해 테스트를 작성하기도 했다)
E2E(End-to-End test)
앞서 E2E 테스트의 단점을 언급했지만, 적절한 수준을 유지한다면 E2E 테스트는 매우 유용한 테스트 기법이라고 생각한다. 아무래도 E2E 테스트의 가장 큰 장점은 실제 사용자와의 인터랙션을 가장 비슷하게 재현할 수 있다는 것이다. 따라서, E2E 테스트는 비즈니스 관점에서 사용자의 주요 경로가 정상적으로 작동하는지 테스트할 때 유용하다.
개인적으로 E2E 테스트가 또 유용하다고 생각하는 부분은 인수 테스트(Acceptance Test)를 작성하는 경우이다. 아직 ATDD 경험이 없지만, 아주 유용한 방법론이라고 생각하고 있다. 인수 테스트는 사용자 관점에서 작성되어야 하므로, E2E 테스트 방식이 적합하다고 생각한다.
인수 테스트 도구로는 주로 Cypress와 Playwright가 사용된다. Cypress는 Electron App을, Playwright는 Chrome DevTools Protocol을 기반으로 동작한다. Playwright는 더 다양한 브라우저(예: 사파리)와 고급 기능(병렬 테스트 및 헤드리스 브라우저 등)을 지원하여 대규모 애플리케이션에 더 적합하다. Cypress는 JavaScript 기반 애플리케이션에만 사용할 수 있다는 제한이 있지만, 설정이 간단하고 가벼워 E2E 테스트를 빠르게 도입하려는 팀에게 유용하다.
정적 테스트
정적 테스트는 말 그대로 코드를 동작시키는 것이 아니라, 정적인 코드베이스를 분석하고 테스트하는 방법으로 코드베이스의 품질을 유지하기 위해 사용된다. 우리가 자주 접하는 린트와 코드 포메터도 정적 테스트에 포함된다. 또한, 보안이나 아키텍처 계층 구조의 준수 여부를 검사하는 등 다양한 유스케이스가 존재한다. 프론트엔드에서는 웹 표준 및 웹 접근성 준수 여부를 검사하는 정적 테스트가 유용하다고 생각한다. AI를 이용한 정적 테스트도 점점 나오는 추세인 것 같은데, 대부분 기업 대상이거나 비용이 비싸서 아직 시도해보지는 못했다.
마무리하며
이번 포스트에서는 프론트엔드 테스트의 '왜'와 '무엇'에 대한 내 생각을 공유해 봤다. 이 글을 쓴 계기는 대부분의 프론트엔드 테스트 관련 글들이 도구 사용법이나 개념에 초점을 맞추고 있어, 실제로 프론트엔드에 테스트를 도입할 때 어려움이 있었기 때문이다. 그래서 구체적인 예시들 들어 설명하는 글이 있으면 좋겠다는 생각이 들어 글을 작성하게 되었다. 비록 의견이 다르거나 부족한 부분이 있을 수 있지만, 그럼에도 불구하고 이 글이 생각을 확장하는 논의의 발판이 되었으면 한다.
또한, 이 포스트에서는 '어떻게'에 대한 부분이 생략되어 있다. '왜'와 '무엇'을 이해하면 '어떻게' 해야 할지는 스스로 결정할 수 있기 때문이다. 이 글에는 포함되지 않지만 '어떻게'에 해당하는 테스트를 더 잘 작성하기 위한 다양한 기법들이 존재하며, 이것들은 각자의 상황에 맞게 학습하고 적용하면 된다. 언제나 'how'는 세부 사항이기 때문이다.
'개발 이야기' 카테고리의 다른 글
| Cypress로 E2E 테스트 작성하기(ft. App action vs Page object model) (30) | 2024.06.12 |
|---|---|
| 프론트엔드에서 로깅은 왜 필요할까?(ft. 의존성 주입과 선언형 프로그래밍) (32) | 2024.06.04 |
| Turborepo로 모노레포에 엔진을 달아보자 (36) | 2024.05.20 |
| 실제 사례로 보는 개발자가 좋은 코드를 작성해야 하는 이유 (0) | 2024.05.02 |
| 소프트웨어 개발의 본질에 대하여 (0) | 2023.09.29 |